Ray.Tune初探(一):分布式超参优化
OVERVIEW RAY
![]()
What is Ray?
Ray 提供了一个简单的通用 API,用于构建分布式应用程序。
Ray通过以下三步完成此任务:
- 为构建和运行分布式应用程序提供简单的基元。
- 使最终用户能够并行化单个计算机代码,很少或零更改代码。
- 在核心 Ray 上包括一个大型应用程序、库和工具生态系统,以启用复杂的应用程序。
Ray Core为应用程序构建提供了简单的基元。
在Ray Core的顶部是解决机器学习中问题的几个库:
- Tune: Scalable Hyperparameter Tuning
- RLlib: Scalable Reinforcement Learning
- RaySGD: Distributed Training Wrappers
- Ray Serve: Scalable and Programmable Serving
A Simple example
Ray 提供 Python 和 Java API。Ray 使用Tasks(functions)和Actors(Classes)两种形式来允许用户并行化代码。这里给出一个官方文档的Python示例,具体可以见A Gentle Introduction to Ray。
1 | # First, run `pip install ray`. |
Waiting for Partial Results
After launching a number of tasks, you may want to know which ones have finished executing without blocking on all of them, as in ray.get. This can be done with wait (ray.wait). The function works as follows.
Tune: Scalable Hyperparameter Tuning
![]()
What is Ray.tune?
Tune is a Python library for experiment execution and hyperparameter tuning at any scale. Core features:
- Launch a multi-node distributed hyperparameter sweep in less than 10 lines of code.
- Supports any machine learning framework, including PyTorch, XGBoost, MXNet, and Keras.
- Automatically manages checkpoints and logging to TensorBoard.
- Choose among state of the art algorithms such as Population Based Training (PBT), BayesOptSearch, HyperBand/ASHA.
- Move your models from training to serving on the same infrastructure with Ray Serve.
工作流程
首先,需要简单地理解一下Ray.tune中的几个重要概念:
- Trial:Trial 是一次尝试,它会使用某组配置(例如,一组超参值,或者特定的神经网络架构)来进行训练,并返回该配置下的得分。本质上就是加入了NNIAPI的用户的原始代码。
- Experiment:实验是一次寻找模型的最佳超参组合,或最好的神经网络架构的整个过程。 它由Trial和AutoML算法所组成。
- Searchspace:搜索空间是模型调优的范围。 例如,超参的取值范围。
- Configuration:配置是来自搜索空间的一个参数实例,每个超参都会有一个特定的值。
- Tuner: Tuner就是具体的AutoML算法,会为下一个Trial生成新的配置。新的 Trial 会使用这组配置来运行。
- Assessor:Assessor分析Trial的中间结果(例如,测试数据集上定期的精度),来确定 Trial 是否应该被提前终止。
- Training Platform:训练平台是Trial的执行环境。根据Experiment的配置,可以是本机,远程服务器组,或其它大规模训练平台(例如,Ray自行提供的平台)
那么你的实验(Experiment)便是在一定的搜索空间(Searchspace)内寻找最优的一组超参数组合(Configuration),使得该组参数对应的Trail会获得最高的准确率或者得分,在有限的时间和资源限制下,Tuner和Assessor会自动地帮助你更快更好的找到这组参数。
快速入手实例
为了快速上手,理解Ray.tune的工作流程,不妨训练一个简单的Mnist手写数字识别,网络结构确定后,Ray.tune可以来帮你找到最优的超参。
Pytorch Model Setup
首先需要搭建一个能够正常训练的模型,这一部分与Tune本身是无关的。
导入一些依赖项:
1 | import numpy as np |
然后使用PyTorch定义一个简单的神经网络模型。
1 | class ConvNet(nn.Module): |
然后定义具体的训练函数和测试函数。
1 |
|
Setting up Tune
现在,需要定义一个可以用于并行训练模型的函数。这个函数将在每一个 Ray Actor (process) 上单独执行。因此,该函数需要将模型的性能传达回Tune主进程中。为此,在训练函数中调用 tune.report,它能够将性能的数值发送回Tune。
1 | def train_mnist(config): |
为超参建立搜索空间后,调用 tune.run 就可以完成一次Experiment了。
1 | search_space = { |
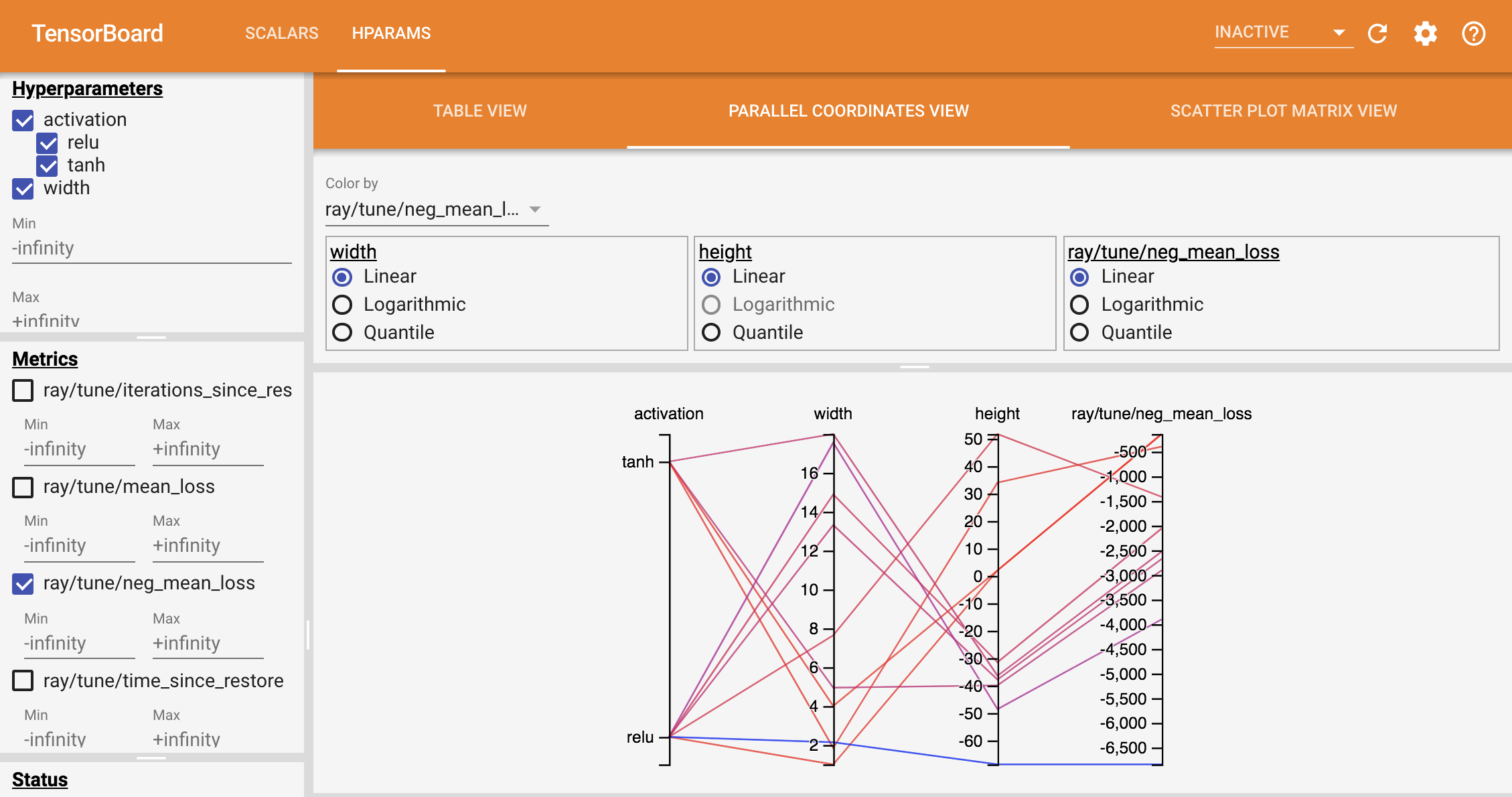
tune.run 会返回一个Analysis Object。它保存了优化过程的数据,可以绘图进行分析。同时每一个trial的数据自动保存在 ~/ray_results 文件夹中,也可以使用Tesnorboard来分析优化过程。
1 | tensorboard --logdir ~/ray_results |