AlphaGO:详解
了解AlphaGO
选出好棋-增强学习Reinforcement Learning
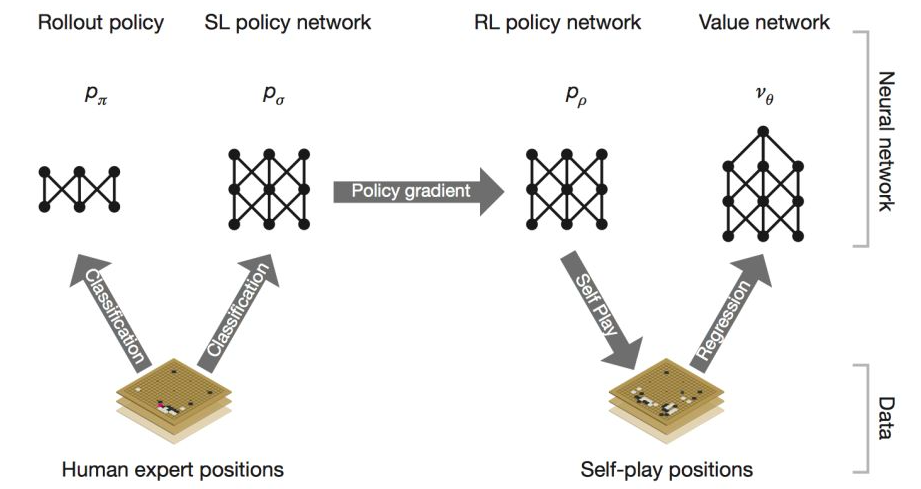
模仿学习
增强学习
“手下一步棋,心想三步棋”-蒙特卡罗树MCTS
围棋问题实际上是一个树的搜索问题,当前局面是树的根,树根有多少分支,对应着下一步有多少对应的落子,这是树的宽度。之后树不断的生长(推演,模拟),直到叶子节点(开始落子)。从树根到叶子节点,分了多少次枝就是树的深度。树的广度越宽,深度越深,搜索所需要的时间越长。如:围棋一共361个交叉点,越往后,可以落子的位子越少,所以平均下来树的宽度大约为250,深度大约150.如果想遍历整个围棋树,需要搜索250的150次方。所以走一步前,需要搜索折磨多次数是不切实际的。
每次AlphaGo都会自己和自己下棋,每一步都由一个函数决定应该走哪一步,它会考虑如下几个点:
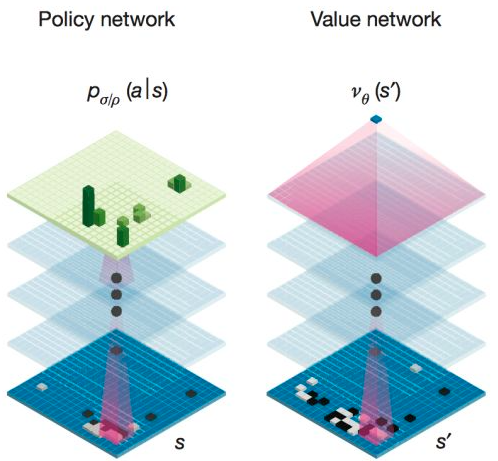
1.这个局面大概该怎么下?(使用SL Policy network)
2.下一步会导致什么样的局面?
3.我赢的概率是多少?(使用Value network+rollout)
首先,“走棋网络”是训练的当前局面s的下一步走棋位置的概率分布,它模拟的是在某个局面下,人类的常见的走棋行为,并不评估走棋之后是否赢棋(区别概率分布与赢棋的概率?)。所以,我们可以假设优秀的走棋方法是在人类常见的走棋范围内的,这样就大大减少了搜索树的宽度。
这时候,使用SL policy network 完成了第一落子,假设走了a1之后,然后对方开始走a2,接着我在走a3.这样一步步的模拟下去…..(这里使用两个SL policy network的自我对弈)假设V(s,a1)赢棋的概率为70%,对方走了V(s,a1,a2)对方赢棋的概率为60%。而走到第三步的时候,我方的赢棋概率V(s,a1,a2,a3)是35%,这时候还要不要在走a1呢?
重新定义V(s)的实际意义:它用来预测该局面以监督学习的策略网络(SL Policy network)自我对弈后赢棋的概率,也就是模拟N次后,AlphaGo认为她走这步棋赢的概率,这个概率是不断的更新。我们用V表示某一局面赢棋的概率。刚开始v(s,a1)=70%,在下完第三步后更新为v*(s,a1)=(70%-60%+35%)/3=15%,这个时候V(s,a1)=15%,已经不是之前的70%了,也就是说这个位置可能不是赢棋的概率最大的位置,所以舍弃。
然而发现,SL Policy network 来进行自我对弈太慢了(3毫秒),重新训练了一个mini的SL Policy network,叫做rollout(2微秒). 它的输入比policy network 小,它的模型也小,它没有Policy network 准,但是比他快。
这就是蒙特卡罗树搜索的基本过程,
1.它首先使用SL policy network选出可能的落子区域,中间开始使用value network来选择可能的落子区域。
2.使用快速走子(Fast rollout)来适当牺牲走棋质量的条件下,通过Fast rollout的自我对弈(快速模拟)出最大概率的落子方案,使得AlphaGo 能够看到未来。
3.使用Value network对当前形势做一个判断,判断赢的概率,使得AlphaGo能够看到当下。可见,MC树融合了policy network 、Fast rollout和Value network,使之形成一个完整的系统。